

原力无限以第一作者单位重磅发布AtomVLA模型:当世界模型学会“替机器人思考”,VLA后训练进入新范式
——原力无限首发具身大脑核心模型,一个基于预测型潜在世界模型的可扩展VLA后训练框架。LIBERO基准97%成功率,真机完成高难度柔性物体操作

论文全文:AtomVLA: Scalable Post-Training for Robotic Manipulation via Predictive Latent World Models
论文地址:https://arxiv.org/pdf/2603.08519
这是原力无限资深研究科学家陈佳玉教授带领团队(主要完成人:孙小权博士)推出的最新研究成果。如果说此前发表的7篇顶会顶刊论文构建的是具身大脑从世界模型、因果推理、运动控制到终身学习的“认知地基”,那么AtomVLA直接瞄准的是一个更尖锐的工程问题——如何让VLA大模型在复杂的长程任务中真正变得可靠?
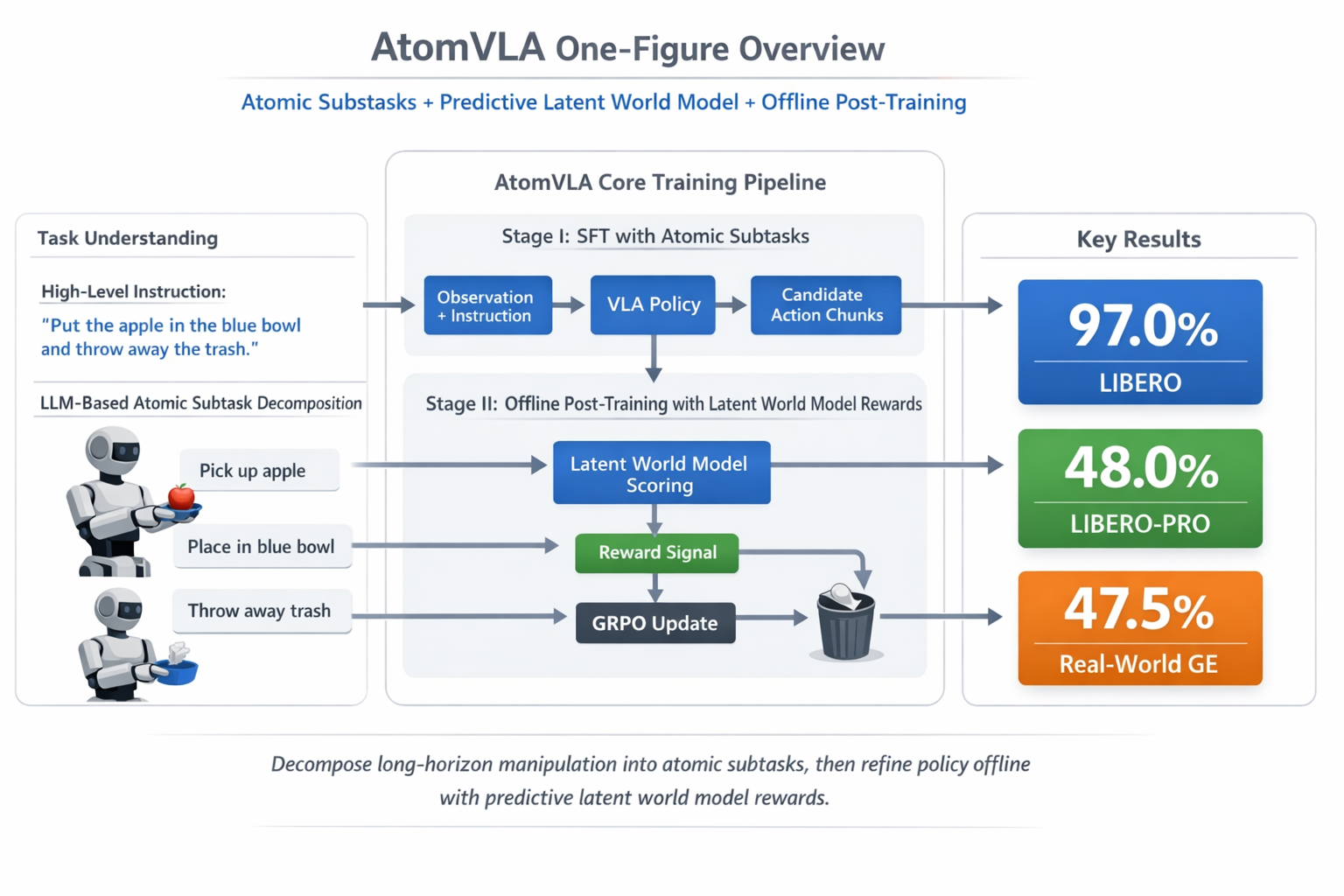
在两大权威基准测试中,AtomVLA取得了LIBERO 97.0%、LIBERO-PRO 48.0%的成功率,均显著超越此前所有基线方法。
在真机平台上,AtomVLA成功完成了叠T恤、叠毛巾等高难度柔性物体操作——这是当前VLA模型中最难完成的真机任务类型之一。
更重要的是,AtomVLA开创性地提出了“原子子任务分解 + 预测型世界模型离线评估 + 离线GRPO后训练”的完整范式,实现了不依赖昂贵真机在线交互的高效策略优化。在全球VLA后训练研究竞争日趋白热化的当下,这一框架提供了一条兼顾性能、效率与可扩展性的全新技术路径,标志着VLA后训练正在从“依赖真机试错”走向“世界模型驱动的离线进化”新范式。
让机器人又好又快地叠一件T恤。
这个任务之所以难,不在于某一个动作的精度——抓取、翻折、对齐、压平,拆开来看都不复杂。真正的致命难点是:它们必须按正确的顺序连贯执行,且任何一步的微小偏差都会像多米诺骨牌一样传导到每一步后续动作,最终导致整个任务崩溃。
这就是VLA模型面临的长程任务(Long-Horizon Task)困境。目前的主流VLA模型有一个结构性的盲区——论文中称之为“指令落地鸿沟(Instruction Grounding Gap)”:
模型只接收到一条高层指令,比如“叠好T恤”。但中间应该先做什么、再做什么、每一步的阶段性目标是什么——没有人告诉它。模型只能凭借训练时学到的模糊经验“盲猜”下一步,误差在每一步悄然累积,最终表现为令人沮丧的执行失败。
更棘手的是,传统的改进方法——让机器人在真实物理环境中反复试错(在线RL)——成本极其高昂、风险不可控,根本无法规模化。
如何在不依赖昂贵的真机在线训练的前提下,让VLA模型在多步长程任务中保持稳定可靠的执行能力? 这个问题,全球的VLA研究者都在寻找答案。

教机器人“分步思考”,再用世界模型在“脑海中”预演
AtomVLA提出了一个两阶段的后训练框架,从两个维度同时破解上述困境:
第一刀:切碎指令——把「一件大事」拆成「一连串不可再分的小步骤」
AtomVLA利用大语言模型将高层任务指令自动分解为一系列细粒度的原子子任务(Atomic Subtask)——“Atom”即取自“不可再分的最小单元”之意,也源自于原力无限的品牌底层释义——原子虽小,构成万物。例如,“将水果放进篮子”被拆解为“伸手接近水果→抓取水果→移动到篮子上方→松开手指”等精确步骤。这些子任务指令随后与原始高层指令一起,作为监督微调(SFT)的训练信号,让模型在学习阶段就建立起“阶段性目标”的显式意识。
这看似直觉,但论文指出,此前的VLA后训练研究中并未有人完整地将subtask-aware机制与后训练管线系统整合。AtomVLA是第一个做到这件事的框架。
第二刀:脑海预演——让世界模型替代真机完成策略优化
仅有分步思考还不够。要进一步优化策略,传统方法需要机器人在真实物理世界中反复试错——代价巨大且不可规模化。AtomVLA给出了一个更优雅的解法:
引入基于V-JEPA2的预测型潜在世界模型(注:即无需生成完整图像,只需在抽象的“特征空间”预测未来的架构,算力成本低)。当VLA模型生成多组候选动作序列后,世界模型不需要真的去执行这些动作,而是在潜在空间中“想象”每一组动作的未来状态,评估哪组动作最接近子任务目标。评分最高的方案获得正向奖励信号,评分最低的作为负向信号,共同驱动离线GRPO(Group Relative Policy Optimization)进行策略优化。
这套机制的核心价值在于:它完全绕开了真机在线rollout,仅通过世界模型在潜在空间中的推理评估,就完成了策略的迭代优化。这意味着——后训练不再需要真机反复试错、不产生设备损耗风险、且可以在标准算力上大规模扩展。

|
基准测试 |
AtomVLA |
此前最佳方法 |
|
LIBERO(标准多步操作) |
97.0% |
94.5% |
|
LIBERO-PRO(高难度泛化测试) |
48.0% |
46.0% |
LIBERO基准97.0%的平均成功率意味着,每100次完整的多步操作尝试中有97次成功。
在专门设计用于测试泛化能力的LIBERO-PRO基准上,AtomVLA的48.0%成功率显著超越所有基线方法(包括π0、MolmoAct、X-VLA等当前代表性VLA模型),提升幅度2个百分点。

四、真机部署:6项任务的严格验证
在Galaxea R1 Lite真机平台上,AtomVLA完成了涵盖基础、困难两个梯度的6项操作任务验证,平均成功率65.8%。在最难的柔性物操作任务中——叠T恤(40%)、叠毛巾(50%)——AtomVLA依然保持了有效的执行能力。
柔性物体操作之所以重要,是因为它直接对应着真实家庭和工厂场景中最常见、也最难的一类任务:叠衣服、整理线缆、分拣布料。AtomVLA在真机上完成这类操作,验证了这一框架从仿真到真实世界的迁移能力。
泛化鲁棒性:四种扰动下的稳健表现
在泛化评估(GE)设置下,研究团队引入了四种典型扰动:物体位置变化、未见过的干扰物体、目标高度变化、指令语言变化。AtomVLA在全部扰动条件下均保持稳健表现,平均成功率47.5%,而同条件下的π0基线骤降至29.2%——AtomVLA的绝对优势达18.3个百分点。这证明了子任务分解+世界模型后训练的联合框架,能有效抑制长程执行中的误差累积,即使面对未见过的环境变化。
VLA后训练正在成为全球具身智能研究最白热化的竞技场。2025年下半年至今,世界模型+RL后训练方向集中涌现了WoVR、World-Env、SOP、GigaBrain等一系列高水平研究。这不是巧合——当VLA模型的预训练能力逐步接近天花板,后训练优化成为决定模型实际可用性的最后一道关卡。
在这场竞赛中,AtomVLA的差异化定位是清晰的:
WoVR、SOP等方案依赖在线rollout或生成式世界模型——要么需要真机交互,要么受制于生成模型的视觉幻觉问题。
AtomVLA选择了一条完全不同的技术路线:预测型潜在世界模型(基于V-JEPA2)在潜在空间中进行评估,不生成像素级图像、不需要真机交互,既规避了生成模型的幻觉问题,又实现了真正的可扩展离线训练。
如果说VLA后训练的1.0时代是“靠真机试错”,2.0时代是“靠生成式世界模型模拟”,那么AtomVLA所指向的,是一个更高效、更可靠的3.0范式——“靠预测型世界模型在潜在空间中直接评估”。
AtomVLA不是一篇孤立的学术论文。它是原力无限具身大脑技术栈中直接面向工程落地的关键模块。
此前,陈佳玉教授团队已通过BA-MCTS、ROMBRL攻克世界模型与鲁棒决策,DSAP实现因果推理与跨域泛化,ETL解决高维运动控制,Continual Distillation构建终身学习能力,RoboTidy打造仿真数据基建,BFM Survey定义行业全景框架——7篇顶会顶刊论文系统构建了从感知到决策到执行到进化的全栈认知地基。
AtomVLA接过的,是下一棒:当底层地基打好之后,如何让VLA大模型在真实复杂任务中变得真正可靠、可扩展、可持续进化? 这正是原力无限全栈自研Hyper-VLA端到端多模态大模型走向工程实用的核心挑战,也是AtomVLA要回答的问题。